 Jede Anwendung basiert auf ein oder mehrere Aktionen, welche zum Teil von verschiedensten Dingen abhängen: Dem User, anderen Systemen, eingegebene Werte etc.
Jede Anwendung basiert auf ein oder mehrere Aktionen, welche zum Teil von verschiedensten Dingen abhängen: Dem User, anderen Systemen, eingegebene Werte etc.
Meist spricht man von einem "Workflow", der in Software umgesetzt werden muss, doch wie bildet man diesen am "effektivsten" ab? If-Else Konstrukte oder "Workflow Engines" wie die Windows Workflow Foundation? Wie steht es mit der Testbarkeit? In diesem Post will ich ein paar Varianten vorstellen, bitte aber wieder ausdrücklich um Feedback, wie ihr dies handhabt.
Was ist bei "mir" alles ein Workflow?
Ohne jetzt auf wissenschaftliche Erklärungen einzugehen, möchte ich meine "Definition" von Workflow niederschreiben: Für mich ist so ziemlich alles ein Workflow. Jeder Login und Registrier-Prozess ist ein Workflow, der mehr oder weniger kompliziert ausfallen kann.
Einen User editieren oder löschen ist auch ein Workflow, da bestimmte Schritte im Code abgegangen werden müssen: Sind die Daten valide, gibt es den User überhaupt, darf der aktuell angemeldet User die Aktion ausführen und und und.
Szenario:
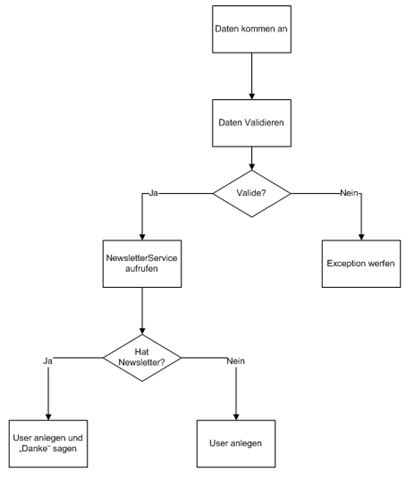
Unser Szenario ist wie beim letzten Mal eine Webanwendung, welche eine 3-Schichten Architektur implementiert. Ein User soll sich anmelden können, dabei wird geprüft, ob er bereits vorher einen Newsletter aboniert hat oder nicht und ob es sich um eine Privatperson handelt oder ein Unternehmen.
Vorher findet natürlich eine Validierung der Daten statt.
Die Logik möchte ich im "Service" halten. Wenn man dies kurz skizziert kommt man auf ein solches Bild - die Abfrage nach Privatperson oder Unternehmen hab ich aus Platzgründen weggelassen - man kann sich hier aber noch beliebig viele andere Bedingungen hinzufügen wenn man das möchte.
Wichtig: Saubere Architektur beibehalten & Testbar bleiben
Das Szenario ist für den Post auch etwas simpler gewählt, allerdings habe ich (wie bereits oben erwähnt) eine solche Struktur und möchte auch nur in den Services im Hintergrund Workflows einsetzen - weder das Repository noch das Front-End muss wissen, wie die Buisnesslogik etwas macht.

Variante A: Per Hand im Code
Ich schreib bei dieser Variante nur "Pseudocode":
public GenericResponse<User> Register(GenericRequest<User> registerRequest)
{
if(userRequest.Value == null)
{
throw new Exception();
}
if(!IValidationService.ValidateRequest(userRequest.Value))
{
throw new Exception();
}
bool hasNewsletter = false;
if(INewsletterService.GetUser(userRequest.Value.Id)) != null)
{
hasNewsletter = true;
}
...
}Vorteil:
- Man braucht nichts neues lernen
_ Volle Kontrolle
- Durch die volle Kontrolle hat man keine Seiteneffekte, dass plötzlich der Service wild auf irgendwelche Datenbanken schreibt
- Testbar (je nach Code ;) )
Nachteil:
- Es kann recht schnell Umfangreich werden
- Es wird mit der Zeit unübersichtlich
Variante B: Man nehme ein Workflow-Engine
Die zweite Variante wäre der Einsatz einer Workflow-Engine, z.B. die Windows Workflow Foundation. Ich möchte jetzt keine Einführung machen, weil ich selber dazu zu wenig weiß.
Es gibt jedoch auf den ersten Blick Designerunterstützung die ganz praktisch ist:
Allerdings scheiden sich die Geister ob sich der Einsatz lohnt oder nicht. Herr Schwichtenberg hat vor langer Zeit mal ein Blogpost über die Guten und weniger guten Dinge der WF geschrieben. Auch auf Stackoverflow ist man sich da nicht so einig ob es nun toll ist oder man lieber auf Version 2 warten sollte.
Zumal die Workflow Foundation die mit .NET 3.0 eingeführt wird mit .NET 4.0 nochmal komplett neugeschrieben wird. Auf den ersten Blick macht die Workflow-Foundation erst mal mehr Arbeit, auch in Rob Conerys MVC Storefront sah ich jetzt nicht unbedingt den Vorteil
Lohnt es sich trotzdem? Ist der Einarbeitungsaufwand hoch? Kann man es gut testen?
Variante C: ?
Weder mit Variante A noch Variante B scheinen mich komplett zu überzeugen. Wobei Variante B voller Tücken, Lernaufwand (+ Migration auf .NET 4.0) und Voodoo ist.
Aber vielleicht hab ich eine geniale Sache vergessen oder die WF ist besser als ich denke - daher bitte ich wieder um euer Feedback :)
Wie würdet Ihr das obere Szenario abbilden?